How It Works
Why Rust Powers 90% of This System
Almost everything you see here runs on Rust.
The server, routing, caching, security, analytics, and content rendering all live inside a single compiled Rust binary built with Actix Web, MongoDB, and Tera.
Posts, schemas, images, and view analytics are stored in MongoDB, while Rust handles the real work: request processing, memory caching, indexing, SEO generation, rate-limiting, and observability. The result is a tight, deterministic engine instead of a maze of services.
The compiled server itself is tiny:
- 18 MB optimized production binary.
- 289 MB debug build with symbols.
That single binary runs the entire blog platform.
But content creation has its own twist.
Meet Ø (Oxygen / O2) — my custom RAG AI model designed to generate article drafts that match my voice and thinking style. Shell scripts take raw ideas, activate the model locally, and generate fresh “oxygen-beer”: raw content that feeds directly into the Rust publishing pipeline. Articles still get revised by hand, but the heavy creative lifting starts there.
The flow is simple:
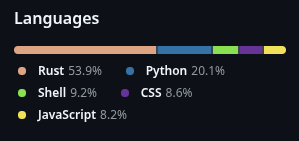
Disconsidering config files, annotations, versioning, and venv files, Rust is close to 90% on the repo.
No bloated “AI platform”. No orchestration circus. Just scripts, a model, and a fast backend.
And here’s the uncomfortable truth: most modern “complex stacks” don’t actually do more than this. They just distribute the same logic across dozens of tools.
Rust lets the system keep state, caches, indexes, and analytics in memory with precision and safety — often more efficiently than entire clusters of services.
The philosophy is simple:
If a problem is deterministic — and most problems can be structured that way — why use a non-deterministic language at all? Everything ultimately runs on a deterministic computer.
When the foundation is deterministic, the system becomes predictable, debuggable, and extremely fast.
That’s the entire idea behind this engine.
What this actually produced:
Over the course of 2 weeks, I designed and built this entire system — backend, content pipeline, and AI integration — starting with only prior experience in web apps.
To validate it, I pushed the system to its limits: Ø was used to generate and iteratively refine a full content pipeline scheduled all the way through October 2028.
The generation process itself ran continuously for 4 days, producing and revising articles with an average time of ~30 minutes per post.
This wasn’t done on high-end infrastructure — the entire pipeline ran on a modest local machine, turning constrained resources into a long-term, scalable content engine.
The model is not generic. It’s a custom RAG-based system designed to simulate my thinking process, follow directive-style inputs, and produce content aligned with my voice and structure.
In practice: this is not “AI-generated content” — it’s a system that amplifies structured thinking into consistent, long-term output.